

Equidad en la Era de la Inteligencia Artificial
La vida no es justa
"...no intrínsecamente, pero es algo que podemos intentar hacerla, un objetivo al que podemos aspirar" (Iain Banks - The Player of Games). La equidad también viene con un mejor sistema económico, bajo consumo de energía, oportunidades y mucho más. La equidad es complicada. En un estudio innovador en 2011 (referencia), los autores examinaron las decisiones de los comités de libertad condicional israelíes y encontraron que la concesión de la libertad condicional era de aproximadamente el 65% al inicio de la sesión, pero caía a casi el 0% antes de un descanso para comer, esto ahora se denomina el efecto del Juez Hambriento.

¿Podría ser que el simple hecho de tener hambre haga que los jueces tomen menos riesgos y, por lo tanto, nieguen la libertad condicional? ¿Cuánta conciencia tenemos sobre los factores externos cuando tomamos decisiones?
La equidad es complicada
Para empezar, los psicólogos argumentan que el tamaño del efecto, que nos indica cuán fuerte y significativa es la relación entre dos variables, es increíblemente alto respecto a este estudio específico (referencia). Es decir, no hay efectos psicológicos plausibles que sean tan fuertes como para provocar este tipo de patrón de datos. El autor proporciona algunos ejemplos de tamaños de efecto similares en psicología:
"Podemos consultar el artículo de revisión de Richard, Bond y Stokes-Zoota (2003) para ver qué tamaños de efecto en la psicología jurídica se acercan a un Cohen’s d de 2. Estos incluyen la observación de que los rasgos de personalidad son estables a lo largo del tiempo (r = 0.66, d = 1.76), que las personas que difieren de un grupo son rechazadas por ese grupo (r = 0.6, d = 1.5), o que los líderes tienen carisma (r = 0.62, d = 1.58)."
Como puedes ver, todos estos efectos son ubicuos. Resulta que hay algunas grandes explicaciones que hacer sobre por qué la concesión de la libertad condicional cae al 0% justo antes de la comida; el patrón de datos respecto al tamaño del efecto es cuestionable cuando se ve desde una perspectiva psicológica.
Empezamos desde cero
Fascinante que a las personas les nieguen la libertad justo antes de que los jueces almuercen, pero ¿por qué? Los investigadores realizaron simulaciones con estos datos y descubrieron algo realmente interesante (referencia).
1. No es que los jueces estén hambrientos lo que los lleva a negar la libertad condicional, sino que, en media, los casos que requieren la concesión de la libertad condicional son más complicados y necesitan más tiempo que aquellos que no la requieren.
2. Aunque los jueces no saben qué caso seguirá, hay múltiples señales en el entorno que permiten deducir qué tipo de caso será el próximo, por lo tanto, los jueces pueden usar su intuición para saber que no deben comenzar un caso complicado que podría ser favorable y terminar con algo más sencillo hacia el final para que pueda finalizar a tiempo y así ir a almorzar.
Los dos puntos anteriores, unidos con cierta censura que los autores originales hicieron en su estudio, fueron simulados juntos y resulta que te lleva al mismo tipo de distribución en cuanto a la aceptación o denegación de la libertad condicional. Después de todo, podría no tratarse completamente de estar hambriento, sino de intuición, prioridades de programación y censura de datos en el estudio.
Equidad y Inteligencia Artificial
Con el advenimiento de algoritmos mejores y más inteligentes surge la pregunta de cómo implementan la equidad. Algoritmos como COMPAS (Perfilamiento de Gestión de Delincuentes para Sanciones Alternativas) están siendo utilizados cada vez más en nuestros sistemas judiciales. Un artículo de revista de 2016 (referencia) examinó cómo COMPAS manejaba los puntajes de riesgo durante la sentencia y encontró que era sesgado; la investigación del equipo encontró que "los negros tienen casi el doble de probabilidades que los blancos de ser etiquetados como de mayor riesgo pero no reincidir realmente".
Un artículo de investigación de 2023 llamado Equal Confusion Fairness: Measuring Group-Based Disparities in Automated Decision Systems (referencia) que propone metodologías para evaluar la equidad, como la prueba de confusión igual, el error de paridad de confusión, metodología asociada para análisis de equidad post hoc, utilizó estas herramientas para evaluar si COMPAS es justo o no.
“Los hallazgos indican que COMPAS no es justo, y existen discrepancias entre diferentes grupos de sexo y raza e grupos interseccionales. Específicamente, los afro-americanos y los caucásicos muestran un comportamiento divergente que es estadísticamente significativo”.

Como puedes imaginar, los problemas encontrados son dobles, primero, el uso de algoritmos sesgados en nuestros sistemas actuales está aumentando, segundo, la equidad es bastante complicada y aún más difícil de entender, ya que incluso los programadores con habilidades avanzadas no necesariamente aprenden sobre la integración de la equidad en su trabajo.
Implementación simple de la equidad en el Código
En el siguiente repositorio de GitHub implementamos un algoritmo de préstamos simple para resaltar ideas simples sobre la equidad. El algoritmo simula datos sesgados en una población e intenta corregir el sesgo aplicando primero un muestro representativo incorporando el mismo número de muestras de cada grupo, y luego prueba la equidad basada en falsos negativos.
Hipótesis de Simulación
Específicamente, el algoritmo está examinando una aprobación de préstamo justa para snowboarders o esquiadores que pueden ser alienígenas o depredadores.

En la media, la simulación tiene más datos sobre alienígenas que sobre depredadores. Además, los snowboarders devuelven préstamos históricos a tasas más altas que los esquiadores. Este sesgo está simulado en los datos.
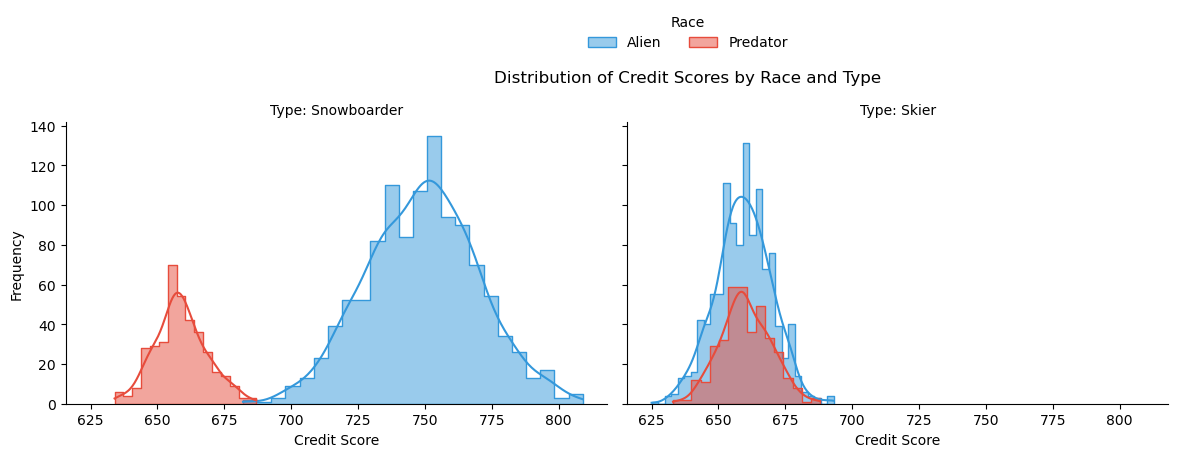 Figura 1: Distribución de los Puntajes de Crédito por Raza y Tipo. Podemos ver que los datos están sesgados hacia los Snowboarders Alienígenas.
Figura 1: Distribución de los Puntajes de Crédito por Raza y Tipo. Podemos ver que los datos están sesgados hacia los Snowboarders Alienígenas.
Muestro representativo
A continuación, veremos cómo tener en cuenta la misma cantidad de muestras para cada subgrupo. Para representar cada subgrupo crearemos una clave de Estratificación especializada que concatenará juntos el Tipo y la Raza.
1biased_df['Stratify_Key&'] = biased_df['Race'] + "_" + biased_df['Type']Y luego simplemente crear un Marco de Datos equilibrado obteniendo el tamaño del grupo más pequeño y asegurando que cada grupo esté representado de manera igualitaria en el marco de datos balanced_df.
1min_group_size = biased_df['Stratify_Key'].value_counts().min()
2balanced_df = pd.DataFrame()
3for group in biased_df['Stratify_Key'].unique():
4 group_subset = biased_df[biased_df['Stratify_Key'] == group]
5 sampled_subset = group_subset.sample(n=min_group_size)
6 balanced_df = pd.concat([balanced_df, sampled_subset], axis=0)Entrenamos un modelo de regresión logística con una precisión de 0.988 (lo cual es bastante bueno) y que producirá la siguiente matriz de confusión.
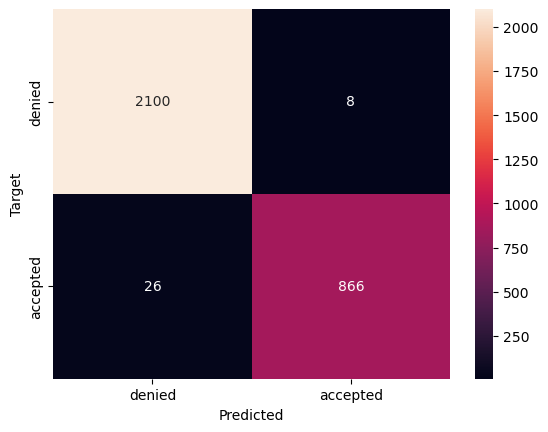 Figura 2: Matriz de confusión con muestreo equilibrado. Muestra 26 falsos negativos. La precisión es de 0.9886666666666667.
Figura 2: Matriz de confusión con muestreo equilibrado. Muestra 26 falsos negativos. La precisión es de 0.9886666666666667.
Podemos ver arriba que tenemos 26 falsos negativos. Es decir, 26 personas deberían ser aceptadas pero fueron rechazadas por el algoritmo. Calcular la equidad entre grupos para los falsos negativos y calcular el sesgo nos muestra las siguientes cifras:
| Snowboarder Depredador | 1.00 |
| Esquiador Alienígena | 1.00 |
| Esquiador Depredador | 1.00 |
| Snowboarder Alienígena | 0.02 |
| Sesgo | 0.9840909090909091 |
Podemos ver que el algoritmo muestra preferencia hacia los snowboarders alienígenas. Raramente los snowboarders alienígenas son rechazados cuando en realidad deberían ser aceptados. Además, el sesgo es bastante alto porque hay mucha diferencia entre la puntuación de sesgo más baja y la más alta.
Ajuste de Pesos
Cada modelo de Inteligencia Artificial tiene pesos específicos, que puedes visualizar como algunos pomos que el modelo puede ajustar para mejorar en la tarea. En la siguiente sección calculamos para cada grupo cuánta atención debe prestar el modelo a ese grupo cambiando los pesos de las muestras. Utilizamos datos del paso anterior para modificar la atención del modelo y así obtener resultados menos sesgados.
1for group_label, bias_rate in sorted_group_fnr_biased:
2 bias_ratio = (bias_rate / (min_fnr + epsilon)) ** power_factor
3 weights[group == group_label] = bias_ratioLuego procedemos a implementar esto en un modelo de regresión logística.
1loanClassifier_with_subgroup_fairness = LogisticRegression(random_state=0)
2loanClassifier_with_subgroup_fairness.fit(X_train, Y_train, sample_weight=weights)Equidad vs Rendimiento
Iteramos con diferentes tipos de factores de potencia sobre cuánto deben considerar los pesos atencionales el sesgo presentado y trazamos un Gráfico de Eficiencia de Pareto, que representa visualmente una situación donde es imposible mejorar la situación de una parte sin empeorar la de otra. En nuestro caso, no podemos optimizar la equidad sin afectar la precisión.
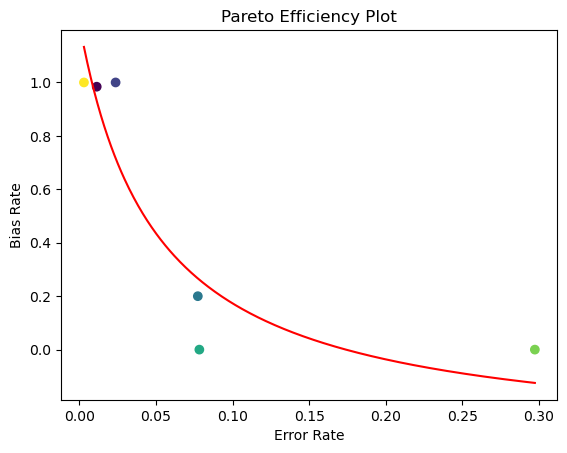
Figura 3: Gráfico de eficiencia de Pareto que nos muestra seis puntos con diferentes tipos de pesos atencionales intentando eliminar el sesgo mientras se mantiene la precisión.
Podemos concluir que existe un compromiso entre el rendimiento, representado por la tasa de error, y la equidad, representada por la tasa de sesgo; por lo tanto, el modelo no es perfecto pero tiene la posibilidad de ofrecer un equilibrio preciso entre rendimiento y equidad de subgrupos. Esta es una lección valiosa para entender. Es imposible tener un modelo con perfecta precisión sin afectar la equidad e imposible tener completa equidad sin afectar el rendimiento.
Puedes extrapolar estos hallazgos en nuestro sistema económico actual. Los mercados libres son excelentes porque le dan a la gente la posibilidad de hacer algo con su vida ofreciendo tiempo/trabajo a cambio de capital, que luego pueden usar como deseen. Esta es una forma sencilla de implementar la equidad en la economía. Al mismo tiempo, cada vez más de nuestros sistemas actuales se orientan hacia el capital, lo que puede verse como un algoritmo de optimización. Esto implementa el rendimiento.
Conclusiones
Hemos visto el Efecto del Juez Hambriento en acción. Al mismo tiempo, echamos un vistazo a diferentes respuestas a ese estudio específico y ampliamos nuestro conocimiento sobre Equidad y Sesgo. Luego continuamos investigando cómo se utiliza la IA en nuestra sociedad actualmente y terminamos con algunas formas sencillas de implementar la equidad en el código.
Subscribe to CogitoMachina
You’ll periodically receive articles about futuristic ideas related to artificial intelligence, the human mind, neuroscience, and consciousness.
