

Fairness In The Age of AI
Life is not fair
"...not intrinsically but it’s something we can try to make it, a goal we can aim for" (Iain Banks - The Player of Games). Fairness also comes with better economic system, low energy consumption, opportunities and much more. Fairness is complicated. In a ground breaking study in 2011 (reference), the authors looked over decisions of Israeli parole boards and they found that the granting of parole was about 65% at the start of the session but it would drop to nearly 0% before a meal break, this is now termed the Hungry judge effect.

Could it be that the simple act of being hungry makes judges take less chances and therefore deny parole? How much awareness we have over extraneous factors in our decision making?
Fairness is complicated
For one, psychologists argue that the effect size, which tells us how strong and significant a relationship between two variables is, is impossibly high regarding this specific study (reference). That is, there are no plausible psychological effects that are so strong as to elicit this kind of data pattern. The author gives some examples of some similar effect sizes in psychology:
"We can look at the review paper by Richard, Bond, & Stokes-Zoota (2003) to see which effect sizes in law psychology are close to a Cohen’s d of 2" those are "the finding that personality traits are stable over time (r = 0.66, d = 1.76), people who deviate from a group are rejected from that group (r = .6, d = 1.5), or that leaders have charisma (r = .62, d = 1.58)."
As you can see, all of these effects are ubiquitous. Turns out, there are some big explanations to do on why granting parole drops to 0% right before the meal, the data pattern regarding the effect size is questionable when viewed from psychological perspective.
Back to square one
Fascinating that people get denied right before judges eat lunch, but why so? Researchers ran simulations on this data and found out something really interesting (reference).
1. It’s not that the judges are hungry that makes them deny somebody parole, but on average, cases that require granting parole are more complicated and necessitate more time than those that do not require parole.
2. Even though the judges do not know which case will follow, there are multiple signals around the environment that makes it possible to deduce what kind of case will be next, therefore the judges can use their intuition to know not to start a complicated case that very well can be favourable and end up with something simpler towards the end such that it can finish in time and go and have lunch.
The above two points joined together with some censorship that the original authors did on their study, were simulated together and it turns that it gets you to the same kind of shape regarding the distribution of accepted/denied parole. After all, it might not be completely about being hungry, but intuition, scheduling priorities and data censorship regarding the study.
AI and Fairness
With the advent of better and smarter algorithms rises the question on how do they implement fairness? Such algorithms like COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) are increasingly being used in our judicial systems. A 2016 journal article (reference) looked on how COMPAS dealt with risk scores during sentencing and found it to be biased, the team investigation found that “blacks are almost twice as likely as whites to be labeled a higher risk but not actually re-offend”.
A research paper from 2023 named Equal Confusion Fairness: Measuring Group-Based Disparities in Automated Decision Systems (reference) which proposes methodologies for assessing fairness such as equal confusion test, confusion parity error, associated methodology for post hoc fairness analysis, used these tools to assess weather COMPAS is fair or not.
“The findings indicate that COMPAS is not fair, and discrepancies exist between different sex and race groups and intersectional groups. Specifically, African-American males and Caucasians show divergent behaviour that is statistically significant”.

As you might imagine the encountered problems are two fold, first the usage of biased algorithms in our today systems is increasing, second, fairness is fairly complicated and even harder to understand since even programmers with advanced skills don’t necessarily learn about integrating fairness into their work.
Simple Fairness in Code
In the following GitHub repository we implement a simple loan algorithm to highlight simple ideas about fairness. The algorithm simulates biased data in a population and tries to correct the bias by first applying balanced sampling thus incorporating the same number of samples from each group, and then tests fairness based on false negatives.
Simulating Hypothesis
Specifically, the algorithm is looking at a fair loan approval for snowboarders or skiers that can be either alien or predator.

On average, the simulation has more data on aliens than on predators. Also, snowboarders pay back historic loans at higher rates than skiers. This bias is simulated in the data.
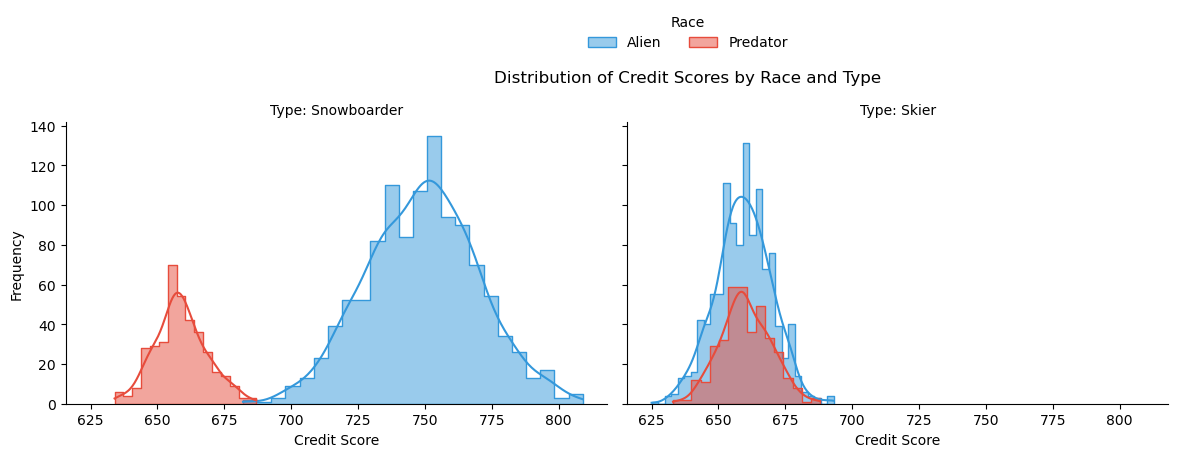 Figure 1: Distribution of the Credit Scores by Race and Type. We can see the data is skewed towards Alien Snowboarders.
Figure 1: Distribution of the Credit Scores by Race and Type. We can see the data is skewed towards Alien Snowboarders.
Balanced sampling
Next, we will look on how to take into consideration the same amount of samples for each subgroup. To represent each subgroup we will create a specialized Stratify key that will concatenate together the Type and Race.
1biased_df['Stratify_Key&'] = biased_df['Race'] + "_" + biased_df['Type']And then simply create a balanced Data Frame by getting the minimum group size and making sure each group is represented equally in balanced_df Data Frame.
1min_group_size = biased_df['Stratify_Key'].value_counts().min()
2balanced_df = pd.DataFrame()
3for group in biased_df['Stratify_Key'].unique():
4 group_subset = biased_df[biased_df['Stratify_Key'] == group]
5 sampled_subset = group_subset.sample(n=min_group_size)
6 balanced_df = pd.concat([balanced_df, sampled_subset], axis=0)We train a logistic regression model with 0.988 accuracy (which is pretty good) and that will produce the following confusion matrix.
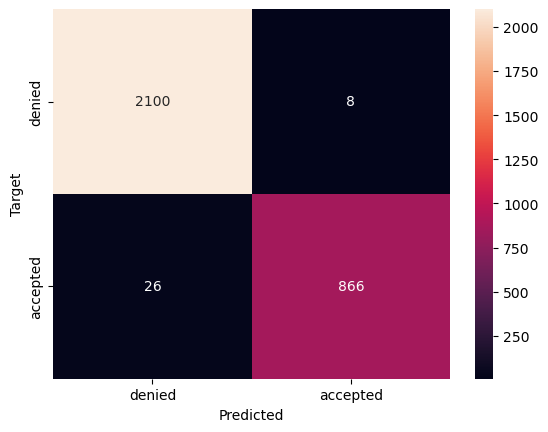 Figure 2: Confusion matrix on balanced sampling. Shows 26 false negatives. Accuracy is 0.9886666666666667.
Figure 2: Confusion matrix on balanced sampling. Shows 26 false negatives. Accuracy is 0.9886666666666667.
We can see above that we have 26 false negatives. That is, 26 people should be accepted but they were rejected by the algorithm. Computing the fairness across groups for false negatives and computing the bias shows us the following figures:
| Predator_Snowboarder | 1.00 |
| Alien_Skier | 1.00 |
| Predator_Skier | 1.00 |
| Alien_Snowboarder | 0.02 |
| Bias | 0.9840909090909091 |
We can see that the algorithm shows preference towards alien snowboarders. Rarely do alien snowboarders get rejected when in fact they should be accepted. Also the Bias is fairly high because there is much difference between the lower bias score and the highest.
Weights Adjustment
An Artificial Intelligence model has specific weights, which you can visualize as some kind of dials or knobs that the model can adjust to get better at the task. In the following section we calculate for each group how much should the model pay attention to that group by changing the sample weights. We use data from the previous step to modify the attention of the model so we get less biased results.
1for group_label, bias_rate in sorted_group_fnr_biased:
2 bias_ratio = (bias_rate / (min_fnr + epsilon)) ** power_factor
3 weights[group == group_label] = bias_ratioThen we got ahead and implement this in a logistic regression model.
1loanClassifier_with_subgroup_fairness = LogisticRegression(random_state=0)
2loanClassifier_with_subgroup_fairness.fit(X_train, Y_train, sample_weight=weights)Fairness vs Performance
We iterate with different kind of power factors on how much the attentional weights should take into consideration the presented bias and plot a Pareto Efficiency Plot which visually represents a situation where it is impossible to make one party better off without making another party worse off. In our case we cannot optimise for fairness without affecting accuracy.
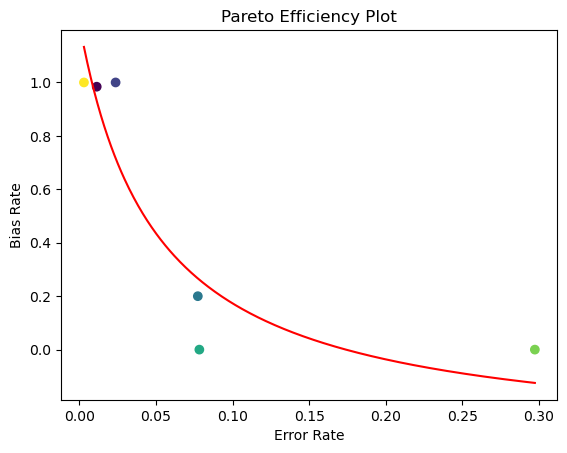
Figure 3: Pareto efficiency plot that shows us six points with different kind of attentional weights trying to eliminate the bias while keeping accuracy.
We can conclude that there is a trade-off between performance represented by the error rate and fairness represented by the bias rate, therefore the model is not perfect but it has the possibility to provide an accurate trade-off between performance and subgroup fairness. This is a valuable lesson to understand. It is impossible to have a model with perfect accuracy without affecting fairness and impossible to have complete fairness without affecting performance.
You can extrapolate these findings in our today's economic system. Free markets are great because they give people the possibility to make something with their life by offering time/work in exchange for capital which they can then use how they please. This is a simple way to implement fairness in economy. At the same time, more and more of our today's systems are drawn towards capital, which can be seen as an optimization algorithm. This implements performance.
Conclusions
We have seen the Hungry Judge Effect in action. At the same time, we took a look at different responses to that specific study and further our knowledge about Fairness and Bias. We then continued to look into how AI is used in our society these days and finished with some simple ways to implement fairness in code.
Subscribe to CogitoMachina
You’ll periodically receive articles about futuristic ideas related to artificial intelligence, the human mind, neuroscience, and consciousness.
